1. 古典密码学问题
1.1 问题1:破解凯撒密码
1.1.1 问题
凯撒密码是最简单的单字母替换加密方案。这是一种通过将字母表中的字母固定向右移动几位来实现的加密方法。解密下面的文本,该文本通过对一个去除了空格的法语文本应用凯撒密码获得:

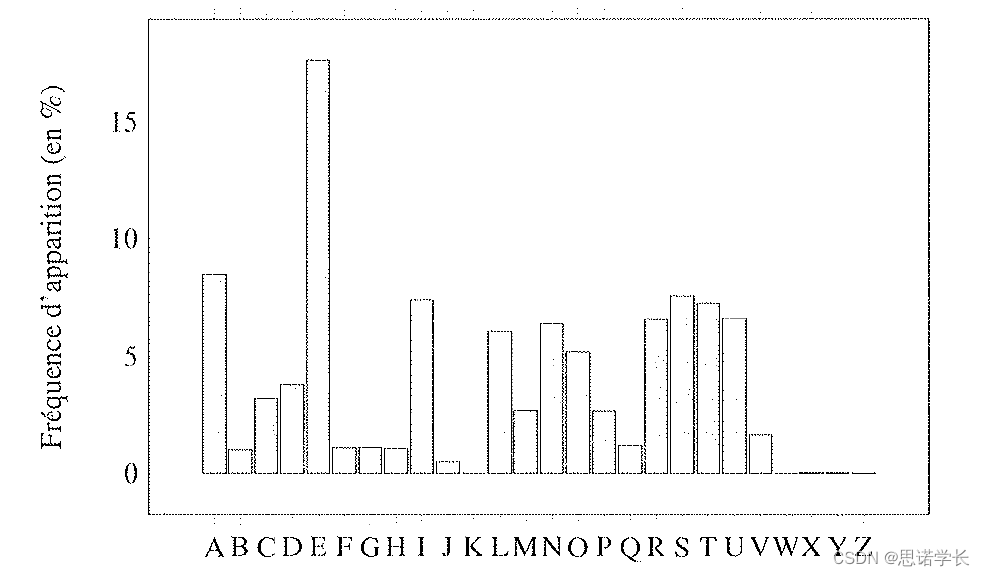
下面的柱状图显示了字母在法语中出现的频率
1.1.2 问题解答
在这个例子中,我们利用频率分析的方法解密了一个使用凯撒密码加密的文本。根据《加密练习和问题》,Damien Vergnaud著,密文中最常出现的字母是“s”,出现了33次,其次是“g”,出现了24次。因此,我们可以推测“s”在原文中对应于法语中最常见的字母“e”,这意味着使用了14个字母的偏移量进行加密。
e = 5 ,s = 19 26-19+5 = 12 所以,s往回退14个或者往前进12个
通过应用这个偏移量,我们得到了明文,通过适当添加空格和标点符号后得到:
“Hors d’ici, rentrez, fainéans ; rentrez chez vous. Est-ce aujourd’hui fête ? Quoi ! ne savez-vous pas que vous autres artisans vous ne devez circuler dans les rues les jours ouvrables qu’avec les signes de votre profession ? —Parle, quel est ton métier ?”
这是莎士比亚的戏剧《尤利乌斯·凯撒》中的第一句台词(M.Guizot翻译成法语的版本)。
通过这个过程,我们看到了凯撒密码解密过程中频率分析的实用性,以及如何通过分析密文中字母的出现频率来推断偏移量,进而恢复出原文。这也展示了经典加密技术在面对系统性分析时的脆弱性。
2. 模相关的问题
2.1 问题2: 扩展欧几里得算法
2.1.1 问题
计算7模40的逆。
2.1.2 逆的概念
在数学和密码学中,模逆的概念是指在模运算的背景下,给定两个正整数和
,如果存在一个整数
使得
除以
的余数为1,那么
就被称为
模
的逆元(或模逆)。用数学符号表示就是:如果
,那么
是
模
的逆。
简单来说,如果你将一个数与它的模逆
相乘,那么在模
下,它们的乘积等于1。这在解密或者某些数学计算中特别有用,因为它允许我们"撤销"乘法操作。
以7模40的逆为例,我们找到的逆是23。这意味着当你将7和23相乘,然后除以40,余数是1。这里的关键点是,不是所有的数字都有模逆。一个数在模
下有逆的充要条件是
和
互质(即它们的最大公约数为1)。
这个概念在密码学中尤其重要,例如在RSA加密算法中,就需要计算模逆来构造私钥。
2.1.3 问题解答
这段解释展示了如何使用扩展欧几里得算法计算7模40的逆元。扩展欧几里得算法不仅能找到两个数的最大公约数,还能找到满足特定线性方程的整数系数。在这个例子中,我们寻找的是满足等式的
值。
扩展欧几里得算法的目的是找到两个整数a和b,使得,其中
是a和b的最大公约数。在计算模逆的情况下,我们想要找到一个数x,使得
。在这个特定的例子中,我们要找的是7的模40逆,即找到一个数x使得
。
2.1.3.1 第一步:使用欧几里得算法进行连续除法
目的是找到7和40的最大公约数(gcd),同时记录下中间步骤。7和40互质,因此7在模40下是可逆的。为了计算7的模40逆,我们将使用扩展欧几里得算法。我们通过连续的欧几里得除法进行。设N = 40,K = 7。
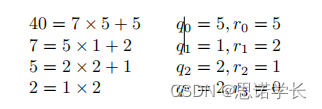
a. 第一次除法
用40除以7,商是5,余数是5。
等式是:
b. 第二次除法
接下来用7除以上一步的余数5,商是1,余数是2。
等式是:
c. 第三次除法
然后是用5除以2,商是2,余数是1。
等式是:
d. 第四次除法
最后用2除以1,得到余数是0,这时停止计算。
等式是:。
通过这个过程,我们发现7和40的最大公约数是1,这也意味着7在模40下是可逆的。我们发现最后一个非零余数r2等于最大公约数GCD(N, K) = 1,因为N和K互质。从欧几里得等式,通过上述步骤,我们发现最大公约数(GCD)为1,这意味着7和40是互质的,因此7在模40下是可逆的。
2.1.3.2 第二步:反向追踪以找到模逆
这一步是扩展欧几里得算法的扩展部分,通过反向使用上述得到的等式来找到7模40的逆。
a.初始化:设置两个系列的初始值为
。
b. 递归计算:根据每一次的除法,我们更新和
的值。通过替代和迭代,我们利用每一步的商
更新
和
。
我们构建系数ai和bi,使得对于所有i,我们有:
aiN + biK = ri
初始化:a-2 = 1,a-1 = 0,b-2 = 0,b-1 = 1。然后我们按以下方式递归进行:
c. 反向追踪来找到模逆
通过迭代计算,我们得到:。
每一步的和
被更新以反映
。
最后,我们找到一个等式,其中,这个等式的
就是我们要找的模逆。
d. 验证:通过迭代我们验证了每一步的,直到我们得到
,这意味着
。
因此,7模40的逆是-17模[40],即23。
通过这个过程,我们最终找到7模40的逆是-17,由于在模40的情况下,-17等同于23,所以7模40的逆是23。
这个过程演示了扩展欧几里得算法不仅能用来计算最大公约数,还能找到模逆,这在密码学和数论中非常有用。
2.1.4 理解初始值的设置
在扩展欧几里得算法中,初始值的设置是为了构建一个系数的递推关系,这个关系可以用来计算两个整数
和
的线性组合,即
,其中
是
和
的最大公约数。
和
:表示在算法开始之前,我们可以将
表示为它自己的1倍加上
的0倍,即
。这是因为任何数乘以1都等于它本身,乘以0则为0。
和
:类似地,这表示我们可以将
表示为它自己的1倍加上
的0倍,即
。
2.1.5 递推关系的作用
这些初始值允许算法通过之后的迭代计算,在每一步都用和
的线性组合来表示当前的余数。通过这种方式,算法不仅计算出
和
的最大公约数,还找到了相应的系数
和
,使得
。
在计算模逆的场景中,比如找到模
的逆,目标是找到一个数
,使得
。这等价于找到
和
,使得
,其中1是
和
的最大公约数。通过递推关系和初始值的设置,扩展欧几里得算法能够逐步构造出这样的
(即模逆)。
这种方法的美妙之处在于,它不仅适用于模逆的计算,还能解决其他需要找到整数解的线性方程问题。初始值的设定是这个递归计算过程正常进行的基础。
2.1.6 结论
通过这个详细的过程,我们可以看到扩展欧几里得算法不仅可以用来找到两个数的最大公约数,还可以用来找到模逆,这在密码学中非常重要。
2.2 问题3:快速幂运算
2.2.1 问题
在RSA加密中,密文是通过以下形式获得的:
其中e是加密指数,N是RSA模数。基于e在2进制下的分解,提出一种快速计算密文的方法。你的方法的复杂性是多少?
2.2.2 问题解答
我们将加密指数分解为2进制形式:
,其中
换句话说,的二进制表示是
,从最低位开始。然后,我们可以按以下方式计算
这意味着我们只需要计算,通过连续的模平方计算,并进行模乘法运算。
需要进行的平方和乘法运算次数对应于的二进制表示的长度,因此复杂度为
。这种算法称为快速幂算法。
2.2.3 快速幂算法解释
想象你有一个数字,你想要计算它的
次方,然后取模
的结果,即
。当
非常大时,直接计算会非常耗时。快速幂算法通过将
分解为2的幂次方的和,来减少计算的次数。
这个方法利用了指数的二进制表示来减少计算的总次数。对于每个二进制位,如果位为1,则将当前的计算结果乘以对应的
。这种方法避免了直接计算
,特别是当
非常大时,直接计算将非常耗时。
2.2.4 如何工作
a. 将转换为二进制:首先,我们将指数
转换成它的二进制形式。比如,如果
,那么它的二进制形式是
。
b. 分解计算:根据的二进制形式,我们可以将
分解。以
为例,我们可以写成
。注意到,我们只需要计算
,然后将相应的结果乘起来。
c. 模运算:在每一步的计算中,我们都取模,以确保结果不会变得太大。
2.2.5 复杂度分析
时间复杂度:算法的时间复杂度主要取决于的二进制表示的长度,即
。这意味着所需的操作次数与
的位数成对数关系,相比直接计算
要快得多。
空间复杂度:除了存储计算结果外,该算法不需要额外的存储空间,因此空间复杂度较低。
快速幂算法是一种高效的指数运算方法,尤其适用于公钥加密和数字签名等领域,其中涉及到大数的指数运算。
2.2.6 算法优势
效率:这种方法比直接计算要快很多,特别是当
很大时。
适用性:它特别适合于加密算法中,如RSA加密,其中需要计算大数的幂次方然后取模。
2.2.7 简单示例
如果我们要计算:
a. 13的二进制是1101
b. 我们计算并记录
c. 根据13的二进制表示,我们组合需要的结果:
2.3 问题4:模幂运算
2.3.1 问题
计算,然后计算
。建议您使用快速幂算法,该算法基于指数的二进制分解,以简化为模平方运算。
2.3.2 问题解答
我们将使用快速幂算法,该算法基于指数的二进制表示。首先计算。
7可以表示为。
所以,
。
现在计算。23的二进制表示为
。
接下来进行连续的模平方计算:
-> 。
->
-> 。
因此,的值可以通过组合上述结果来计算:
2.3.3 解释
快速幂算法通过将指数分解为2的幂次和,然后计算基数的这些幂次的模乘积,从而有效地计算模幂。
该方法特别适合于处理大指数幂的情况,因为它将问题分解为一系列更小的、更易于计算的步骤。
算法的效率来自于两个关键点:指数的二进制分解以及模平方计算,这些都显著减少了必要的计算量。
在这个例子中,我们首先计算了,然后使用相同的方法计算了
,展示了快速幂算法的实际应用和效率。
3. 非对称加密协议
3.1 问题5: Diffie-Hellman密钥交换
3.1.1 问题
a. 验证是否为乘法群
的生成元。
b. 如果Alice和Bob使用Diffie-Hellman协议,其中 且
,且他们选择的随机数分别为
和
,那么他们建立的共享秘密是什么?
3.1.2 问题解答
3.1.2.1 问题a
首先,我们需要验证 是否能作为乘法群
的生成元。乘法群
包含了所有小于11的非零整数,并且与11互质。由于11是素数,这个群就是集合
,共有 10 个元素。我们将计算
的连续幂次(模11):
我们确实枚举了循环群的所有元素。因此, 是这个群的生成元。
3.1.2.2 问题b
Alice的私钥是。相应的公钥是
。
Bob的私钥是。相应的公钥是
。
Alice和Bob共享的秘密是 (Alice计算的值),等于
(Bob计算的值):
3.1.3 解释
这个过程是Diffie-Hellman密钥交换协议的实施例子,它允许两个通信方在不安全的通道上建立共享秘密。通过选择一个公共的基和一个公共的模数
,以及各自选择一个私钥
和
,双方各自计算出一个公钥并交换。
然后,双方分别使用对方的公钥和自己的私钥计算出相同的共享秘密。这个秘密接下来可以用作加密通信的密钥。重要的是,即使一个攻击者知道了
,如果没有一个私钥,计算出共享秘密
在计算上是不可行的。
在这个例子中,Alice和Bob成功地通过Diffie-Hellman协议建立了共享秘密9。
3.2 问题6: RSA
3.2.1 问题
设,
,
,并且
。
计算使得
。
加密消息 并验证结果通过解密。
3.2.2 问题解答
3.2.2.1 计算φ(n)
φ(n) = (p - 1) * (q - 1) = (3 - 1) * (13 - 1) = 2 * 12 = 24
3.2.2.2 使用快速幂算法加密消息
给定消息,指数
,模数
,我们想计算
。
将29转换为二进制表示:
计算所需的连续平方值(模39)并累乘那些对应二进制位为1的值:
(因为)
(因为))
根据29的二进制表示,我们需要
所以,加密后的消息。
3.2.2.3. 解密验证
需要计算 模24的逆,或等效地,计算5模24的逆。我们很容易找到
。在一般情况下,需要使用扩展欧几里得算法来计算模逆。
使用扩展欧几里得算法来计算模逆实际上是寻找整数和
,使得
,其中
是
和
的最大公约数。对于模逆的计算,我们想要找到一个数
使得
,或等价于找到
和
,使得
。
这里我们用,
,我们想要找到a模b的逆。
m=
mod n = 2
3.2.2.4 步骤
初始化:设置两个方程的初始值:。这些是算法开始时方程
的系数,表示在每一步的计算中a和b的线性组合。
辗转相除:在每一步,应用辗转相除法:计算a除以b的商q和余数r,即。
更新系数:用来更新
的值,用
来更新
的值。具体地,新的
,新的
。
迭代:将a设置为原来的,b设置为原来的r,
更新为
,
更新为
。
直到:重复步骤2-4,直到。此时,a等于
,并且上一步的
(现在是
)是所求的模逆。
3.2.2.5 示例
假设我们要找到29模24的逆。我们知道,
。
a. 因为,我们实际上是在找5模24的逆(因为
)。
b. 应用扩展欧几里得算法:
q0=4 ro= 4
q1= 1 r1= 4
d取5
3.3 问题7:RSA的解密
3.3.1 问题
你截获了一个密文,这个密文是使用公钥
和
通过RSA加密得到的。明文信息是什么?
3.3.2 问题解答
在这里,我们很容易找到的因数
和
。因此,我们知道
。
解密指数是
模的逆。我们很容易找到
,因此明文消息为:
实际上,的二进制分解如下所示:
通过连续的模平方计算,我们发现:
因此,明文消息为:
4. LFSR(线性反馈移位寄存器)
一个长度为L的二进制LFSR的工作原理如下:每个时钟周期,位构成寄存器的输出,其他位向右移位;放入寄存器左边单元的新位
由线性函数给出:
其中系数是二进制的。寄存器的反馈多项式被称为多项式
,在
中 。
4.1 问题8.1
4.1.1 问题
根据寄存器的初始状态,给出由反馈多项式产生的二进制序列。它们的周期是什么?
4.1.2 解答
考虑反馈多项式的LFSR。
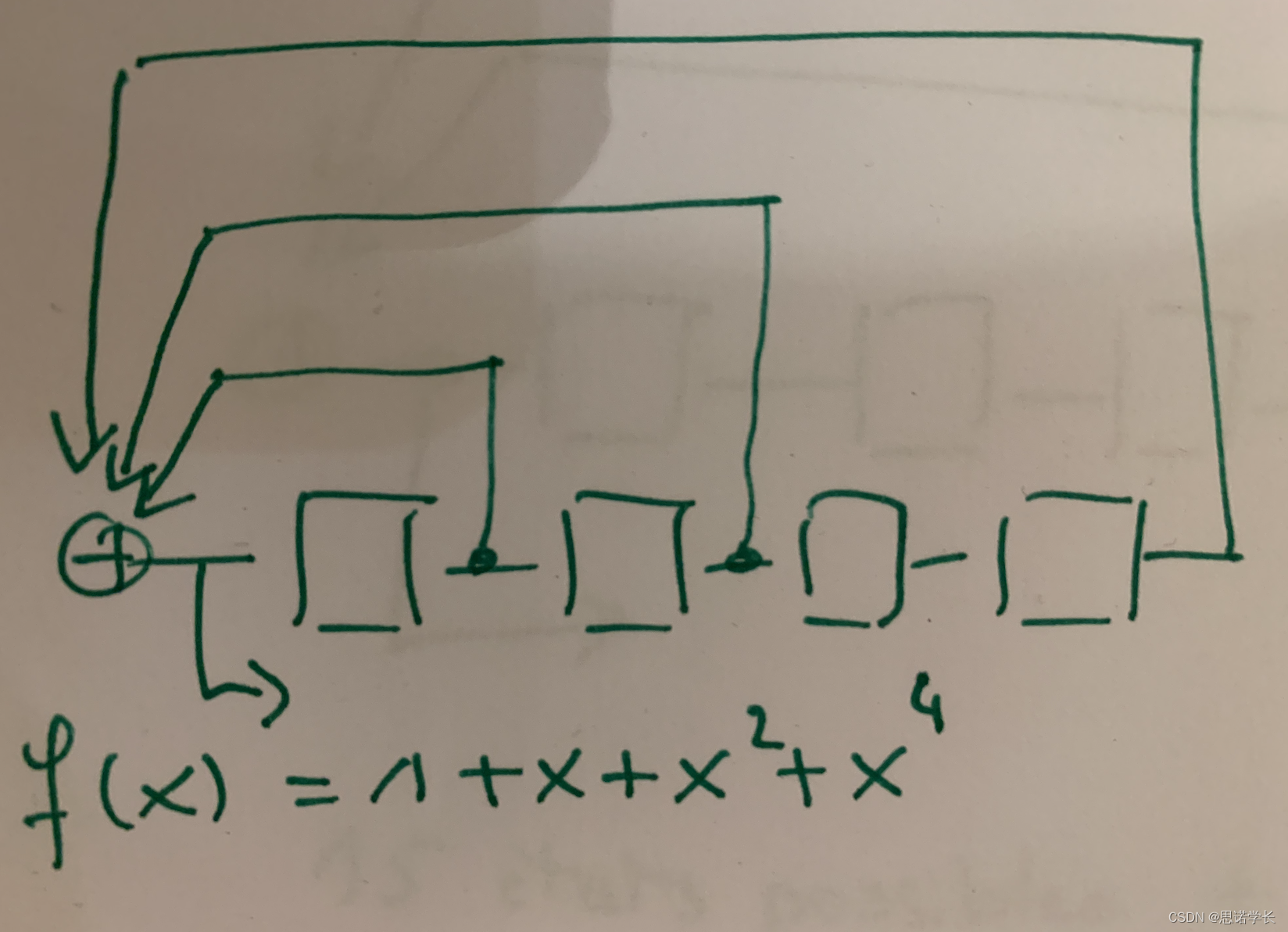
它有个存储元素,因此寄存器有
个可能的状态(15个非零状态和一个“全零”状态)。
假设寄存器初始化为(0001)。其后续的值是:
0001
1000
1100
0110
1011
0101
0010
0001
...
在这种情况下,我们找到了一个周期为7的序列,LFSR产生的序列是0110100 0110100 ...
我们还有状态(1111),在这个状态中我们无限期地保持;产生的序列是1111111 .......
状态(0000),在这个状态中我们也无限期地保持;产生的序列是0000000 ......
考虑一个不在已列举状态序列中的初始状态,例如(0111)。如果我们从这个状态开始,我们将遍历以下循环:
0111
0011
1001
0100
1010
1101
1110
0111
......
我们得到一个周期为7的序列,产生的序列是00101110 00101110 ...
因此,我们确实枚举了所有16个可能的状态。
4.2 问题8.2
4.2.1 问题
对于反馈多项式和
,提出相同的问题。
4.2.2 解答
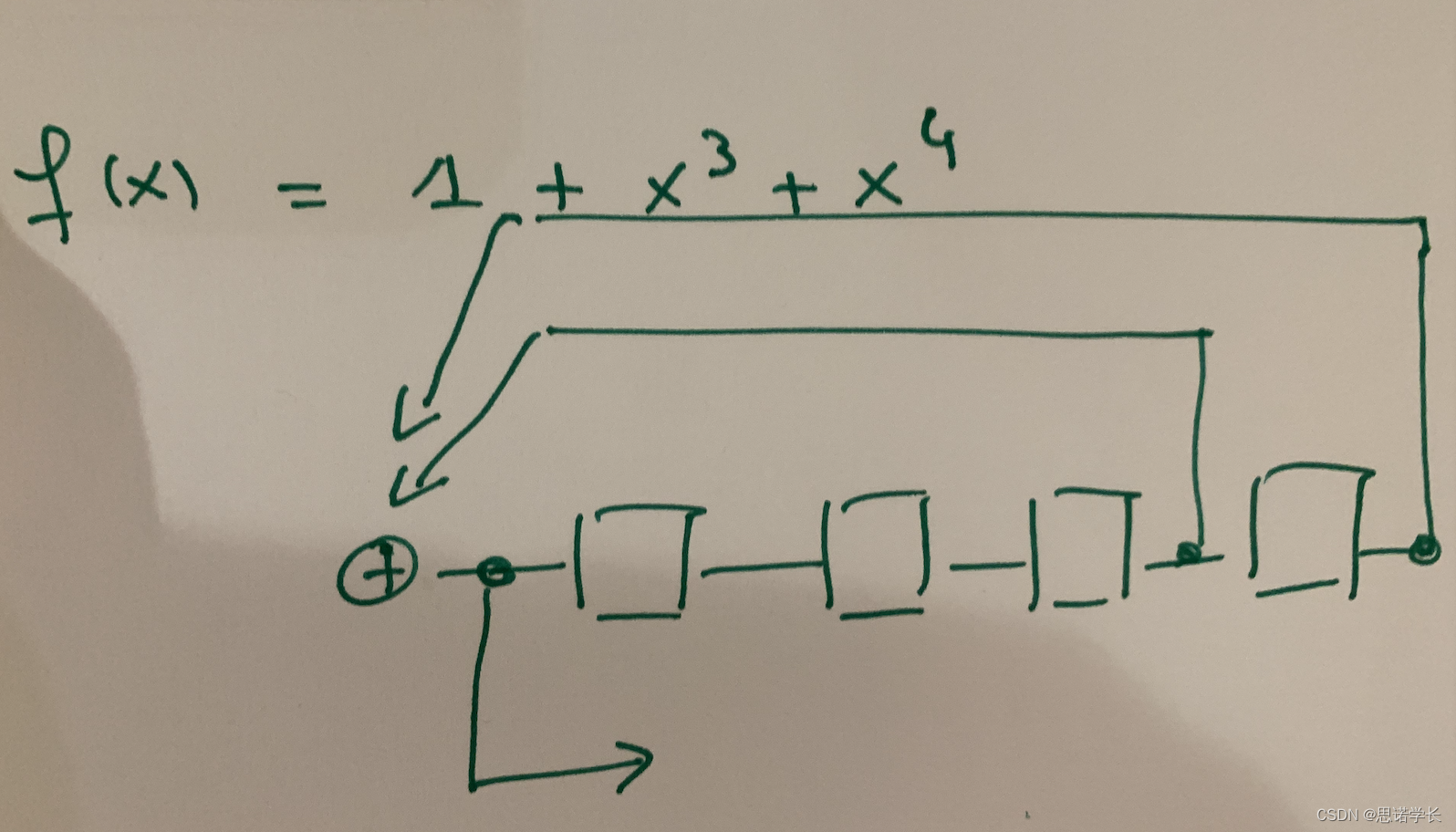
现在考虑反馈多项式。
有4个存储元素,因此除了 全零 状态外还有15个可能的状态。如果处于状态(0000),则会无限期地保持该状态。
假设我们从状态(0001)开始。我们将遍历以下循环:
0001
1000
0100
0010
1001
1100
0110
1011
0101
1010
1101
1110
1111
0111
0011
0001
...
我们得到一个周期为15的序列。我们已经枚举了所有(非零)可能的状态。产生的序列是010011010111100 ...
4.3 问题8.3:LFSR的周期性
4.3.1 问题
解释为什么LFSR产生的二进制序列从某一特定排名开始是周期性的(最终周期性的)。
由长度为L的LFSR产生的序列可能有的最大周期是多少?为什么?
4.3.2 问题解答
LFSR(线性反馈移位寄存器)产生的二进制序列具有周期性的原因是因为它在一个有限的状态集合中进行迭代。简单来说,LFSR在每一个时钟周期将当前的状态进行某种形式的线性变换,生成一个新的状态,同时产生一个输出位。由于状态的数量是有限的,所以经过一定数量的迭代后,LFSR必然会返回到一个之前的状态。一旦这种情况发生,状态序列就会开始重复,导致输出的二进制序列也开始周期性地重复。
对于一个长度为的LFSR,理论上最大的周期长度是
。这个最大周期称为满周期(Full Cycle),指的是在回到初始状态之前,LFSR能够遍历其所有可能状态的情况,除了全零状态。全零状态被排除,是因为一旦LFSR进入全零状态,它就无法自行离开这个状态(因为线性变换的结果还是零),所以它不被计入周期性序列中。
因此,无论LFSR的起始状态如何(除全零状态外),它最终都会进入一个循环,其中包含了一系列唯一的状态,这个循环之后会重复。这就解释了为什么LFSR生成的序列是周期性的。最大周期是在理想条件下,即使用了一个“好”的反馈多项式时才能达到的,这个多项式能确保遍历所有非零状态。
5. RSA问题
5.1 问题9
我们了解到共享RSA模数是危险的,假设在一个RSA加密系统中,我们给两个不同的用户分配了一对(公钥,私钥):和
,它们与同一个RSA模数
相关联。
5.1.1 问题9.1
5.1.1.1 问题
证明一个用户可以轻松地从他自己的一对和模数
中恢复
的因子分解。
5.1.1.2 问题解答
如果我们知道和
,那么很容易分解出
,也就是找到因数
和
。
事实上,我们知道乘积。此外,我们知道
因此,整除
,即存在一个整数
使得:
由于通常很大(典型为1024位),
很小。我们可以通过对小值
进行连续尝试来找到整除
的
。
一旦我们确定了一个可能的值,我们可以很容易地推导出
的和。事实上:
我们知道和和乘积
。我们可以通过解一个二次方程来推断出
和
:
这个过程基于二次方程的求根公式。我们已经得到了两个关键信息:和和乘积
。这是因为在RSA加密系统中,模数
,而
。
由于是未知的,我们可以设
为一个二次方程的根,设x代表p或q,那么根据代数基本定理,x满足方程:
这里的系数和
分别对应于二次方程的标准形式
中的b和c。
由于我们已经计算出:
将和
的值代入二次方程,得到:
这个方程描述了p和q,作为未知数的值,必须满足的条件。通过解这个二次方程,我们可以找到p和q的值,这是因为p和q是方程的根。方程的解由以下公式给出:
在这种情况下,,代入上述公式就能求出p和q。这个过程利用了已知的
和
值,以及RSA加密系统的性质,从而允许我们推导出p和q。
两个根必须是整数。如果不是,意味着我们对的值有误,需要重试。
5.1.2 问题9.2
5.1.2.1 问题
我们可以从中得出什么关于系统安全性的结论?
5.1.2.2 问题解答
从中我们可以推断出,用户不应该共享相同的模数。因为这样一来,Alice就可以很容易地利用她自己的密钥对来分解模数
。一旦她分解了模数
,她就能从Bob的公钥
中恢复出Bob的私钥
。
5.1.3 问题9.3
现在假设在系统中,给一组相互信任的用户分配了相同的RSA模数。我们将看到,一个外部攻击者可以轻松攻击这个系统。假设向两个用户发送同一条消息,并使用他们的公钥
和
进行加密,这两个公钥是互质的。外部攻击者可以从密文和
中恢复明文m。
5.1.3.1 问题
陈述和
满足的贝祖等式(Bézout's Identity)。攻击者可以使用哪种算法来找回这个等式的系数
和
?
5.1.3.2 贝祖等式
贝祖等式表明,如果和
互质,那么存在整数
和
,使得
。攻击者可以使用 扩展欧几里得算法 来找到这样的
和
,这个算法不仅可以计算两个数的最大公约数,还能找到满足贝祖等式的
和v。
5.1.4 问题9.4
5.1.4.1 问题
外部攻击者为什么要计算?
5.1.4.2 问题
为什么计算?
这个操作基于模下的乘法性质,以及公钥
和
以及它们的系数\(u\)和\(v\)满足贝祖等式。由于
和
,那么基于
,我们可以通过计算
来还原
,因为:
这个方法允许攻击者,只要他知道两个密文和\(c_2\)以及相应的公钥
和\(e_2\),就可以恢复出原始消息
,这突显了在相同的模数下使用不互质的公钥的潜在危险。
5.2 问题10:费马攻击
RSA中不应选择太接近的质数因子p和q
在RSA中,选择过于接近的质数因子p和q(比如说,使得)是一个坏主意。在这种情况下,可以相对快速地分解出
。
5.2.1 问题10.1
5.2.1.1 问题
假设,
(备注:我们总可以假设
)。那么
的值是多少?
5.2.1.2 问题解答
计算,
,展开后,我们得到
由于,所以
。
5.2.2 问题10.2
5.2.2.1 问题
由此推导出分解的方法。
5.2.2.2 问题解答
因此,我们有,而且我们知道
是小的。注意到
,其中
是小的。
我们将选择为从
开始的连续整数值,并测试
是否是一个完全平方数。因此,我们选择
,然后是
,等等。如果
是一个完全平方数,我们就可以找到
的值,然后计算
和
。
这种攻击被称为费马攻击。它利用了如果和q非常接近,那么
将会是一个小数,这样可以通过枚举t的值并检查
是否为完全平方数来有效地找到p和q。
这种方法在和q足够接近时特别有效,因为在这种情况下,不需要尝试太多的t值就能找到满足条件的t和s,进而得到
和
。
5.2.3 问题10.3
5.2.3.1 问题
编写实现这种攻击的代码。使用这种方法分解N=1607363。
5.2.3.2 问题解答
实际上,要实施这种攻击,我们需要能够估计或知道s和t的值。在实际情况下,s和t不容易直接获取,但如果和
非常接近,我们可以尝试使用近似方法或者数学技巧来获取它们,从而分解
。
以下是一个简化的代码示例,用于尝试分解特定形式的:
p = 1117 et q = 1439.
请注意,这个方法和代码是基于和
足够接近的假设。对于一般的RSA模数,需要采用更复杂的分解算法,如费马分解法、Lenstra椭圆曲线分解法或其他高级算法。
5.3 问题11 RSA密钥生成器
5.3.1 问题背景
这里是一个用Java编写的RSA密钥生成器
import java.io.*;
import java.math.BigInteger;
import java.util.Random;
class genRSA {
public static void main(String arg[]) {
// 定义用于存储质数P、P-1、质数Q、Q-1、模数N、欧拉函数PHI、公钥E和私钥D的变量
BigInteger P, P1, Q, Q1, N, PHI, E, D;
Random alea = new Random(); // 创建一个随机数生成器
E = BigInteger.valueOf(65537); // 将E初始化为常用的公钥指数65537
// 生成质数P
do {
// 生成一个512位的随机质数P
P = new BigInteger(512, 20, alea);
P1 = P.subtract(BigInteger.ONE); // 计算P-1
// 确保P-1和E互质(即最大公约数为1)
} while (!P1.gcd(E).equals(BigInteger.ONE));
// 生成质数Q,过程与生成P相似
do {
Q = new BigInteger(512, 20, alea);
Q1 = Q.subtract(BigInteger.ONE);
} while (!Q1.gcd(E).equals(BigInteger.ONE));
N = P.multiply(Q); // 计算模数N,为P和Q的乘积
PHI = P1.multiply(Q1); // 计算欧拉函数PHI,为(P-1)*(Q-1)
D = E.modInverse(PHI); // 计算私钥D,为E关于PHI的模逆
// 输出生成的密钥对和模数
System.out.println("n = " + N.toString(16)); // 模数N
System.out.println("e = " + E.toString(16)); // 公钥E
System.out.println("d = " + D.toString(16)); // 私钥D
}
}
5.3.2 问题
a. 根据您的看法,变量E代表什么?E的汉明重量(1的比特数)是多少?为什么选择这个值?
b. 变量P和Q代表什么?定义它们的do ... while (...)循环的作用是什么?
c. 生成的RSA密钥的大小是多少?
d. 解释为什么这个生成器不能提供足够的安全性,并提出一个您认为可行的攻击方法及其复杂度评估。
5.3.3 问题解答
a. E代表加密指数。注意65537等于,其汉明重量为2。这意味着,计算模幂
只需要进行4次模平方和一次模乘法。因此,加密过程非常快速。此外,65537是一个质数,因此相对容易找到质数
和
,使得
和
与
互质
汉明重量(Hamming Weight)是信息论中的一个概念,指的是一个二进制数(比特串)中数值为1的位数。换句话说,就是一个二进制数中 1 的数量。例如,二进制数101101的汉明重量是4,因为它包含四个 1 。
在加密学和编码理论中,汉明重量常被用于衡量信息的特定属性,比如密钥或者密码的复杂度。在一些加密算法中,汉明重量也被用于分析算法的安全性,例如在侧信道攻击中,攻击者可能会利用处理不同汉明重量数据时设备功耗的差异来推测密钥信息。
b. P和Q是生成密钥模数的质数因子。循环的目的是确保
和
与
互质,这样
就可以在模
下可逆。
c. P和Q是512位的整数。因此,N是一个1024位的整数。由于是一个1024位的整数,所以解密密钥
的大小也是1024位。
d. 这个生成器的安全性不足的原因在于,随机数生成器是根据当前日期初始化的。如果可以估计出RSA密钥对生成的日期(例如,通过证书的创建日期),那么就可以通过使用生成日期附近所有的日期来初始化随机数生成器,直到生成的质数P是N的一个因子为止。即使对生成日期的估计有一年的不确定性,这意味着需要遍历的种子数量少于(即少于35位的熵空间),这是完全可行的。
因此,如果攻击者能够估计出密钥对的生成时间,并且随机数生成器的种子空间相对较小,那么攻击者就有可能恢复出质数和Q,从而破解RSA加密。这突显了在密钥生成过程中使用强大、不可预测的随机数源的重要性。
5.4 问题12:RSA-CRT或如何通过中国剩余定理加速RSA解密
5.4.1 问题背景 —— 中国剩余定理
比较在这种情况下加密和解密的计算成本。为了加速解密过程,我们可以依赖于中国剩余定理(Chinese Remainder Theorem, CRT)。
使用通常的表示法,,其中
和
是大质数,是RSA的模数。
是加密指数,
是解密指数。我们有
和
,其中
是明文消息,
是密文。
在RSA-CRT中,我们定义:
私钥中存储的量为。
解密时执行以下操作:
能够根据上述公式实际找回,是由中国剩余定理得出的。更准确地说,这是根据CRT,对于如下同余方程组的唯一解的Garner表示法的模
:
我们承认Garner公式。
5.4.2 问题12.1
5.4.2.1 问题
在RSA中,加密指数通常选择为65537。为什么?
5.4.2.2 问题解答
e = 65537 = 在二进制中的表示为(10...01)(17位)。这是一个非常小的数,因此模幂运算(加密)的计算非常快。此外,由于65537是一个质数,因此很容易找到使得e与
互质的质数
和
(这样e就可以模
可逆)。然而,
模
)的逆d非常大(与
同数量级)。因此,使用此加密指数e的解密过程比加密过程慢得多。
5.4.3 问题12.2
5.4.2.1 问题
为什么我们有 和
是成立的?
5.4.2.2 问题解答
5.4.2.2.1 对m的分析
我们有其中
为整数)。
因此,我们可以推断出以及
5.4.2.2.2 对de的分析
此外,由于(其中
为整数)
所以且
,
因此,且
5.4.2.2.3 欧拉定理
,
,
,
根据欧拉定理,我们知道且
。我们可以推断出
以及
。
因此,是如下同余方程组的(模
下唯一的)解:
且
。
Garner公式提供了根据和
计算
的方程。
5.4.2.3 详细解答
在RSA中,我们有一个密文,通过加密指数e和模数
来加密明文消息m,即
。要解密密文,我们使用解密指数d来计算
。现在让我们详细解释上述过程以及它是如何通过中国剩余定理(CRT)加速的。
5.4.2.3.1 解密过程和中国剩余定理的应用
基础等式:我们有(其中k为整数)。这意味着,解密过程可以在模
和模
下独立进行,也就是说,我们可以得到
以及
。
d和e的关系:由于(其中k为整数),我们知道
且
。因此,
等同于模
下的
和模
下的
。
欧拉定理:欧拉定理告诉我们,且
。根据这一定理,我们知道
且
。
解的唯一性:根据中国剩余定理,是以下同余方程组的唯一解(模
):
且
,其中
和
分别是模p和模q下的解。
Garner公式:Garner公式提供了一种从和
计算m的方法。具体来说,我们首先计算模
和模q下的解密结果,然后使用Garner公式和预先计算的参数(如
)来合并这些结果,以得到模
下的明文m。
5.4.2.3.2 中国剩余定理(CRT)加速解密的原理
通过在较小的模p和模q下独立进行解密操作,然后合并结果来得到最终的明文,RSA-CRT方法能显著减少解密操作的计算量。由于在较小的模数下进行运算比在大模数N下进行运算更快,这种方法可以大幅提高RSA解密的效率。
简而言之,RSA-CRT方法通过利用中国剩余定理,使得RSA解密过程可以在较小的数域内进行,从而加速解密。这种方法特别适用于具有大密钥长度的RSA应用,能有效减少解密所需的计算资源。
5.4.2.3 欧拉定理
欧拉定理是一个关于数论的重要定理,它描述了一个整数和一个质数之间的关系。这个定理的一个关键结论是:如果是一个正整数,
是一个与
互质的整数(即
和n的最大公约数为1),那么a的欧拉函数
次幂除以
的余数为1。用数学语言表示就是:
在RSA加密中,特别是使用中国剩余定理(CRT)进行优化的情形下,欧拉定理被用来加速解密过程。以下是该过程的简化解释:
5.4.2.3.1 欧拉定理的应用
假设我们有两个质数p和q,它们是RSA模数的因子。根据欧拉定理,我们可以推导出:
对于任何整数,
对于任何整数c,
5.4.2.3.2 如何应用于RSA-CRT解密
在RSA-CRT中,我们不直接使用解密指数d进行解密,而是使用分别模和模q-1的d的等价值
和
。这里,
和
是根据下面的等式计算的
由于,根据欧拉定理,我们知道:
这意味着,我们可以分别在模p和模下计算c的
次幂和\(d_Q\)次幂,这两个结果分别与直接在模
下计算
得到的结果相同。
5.4.2.3.3 为什么这很重要
通过分别在模p和模q下计算,我们可以显著加速解密过程,因为这两个模的数值比模小得多。这样,我们就可以利用中国剩余定理将模p和模q下的解密结果合并,快速得到在模
下的解密结果。
简而言之,欧拉定理允许我们在较小的模下进行计算,从而加速RSA的CRT优化解密过程。通过分别对每个质数因子执行运算,然后合并结果,我们可以更有效率地解密,而不是直接在较大的模下进行解密。
5.4.3 问题12.3
5.4.2.1 问题
使用RSA的形式的解密计算时间与使用上述RSA-CRT方法的解密计算时间的比率是多少?
5.4.2.2 问题解答
RSA-CRT的计算复杂度较低,因为RSA-CRT中的幂运算是根据和
计算的,它们与
同数量级。
模幂运算的计算时间与模数的二进制表示长度的立方成正比。
如果模数用
位表示,则
和
的长度大约为
位。
在经典RSA中,解密的计算成本将是。
在RSA-CRT中,进行了两次模幂运算(一次是模,另一次是模
)。因此,计算成本大约为
。使用中国剩余定理,我们在计算上获得了4倍的提升。模幂运算的计算成本与模数的大小(位数)呈立方关系。
6. 公钥密码学中的问题
6.1 问题13:匿名数字货币
提出了一种加密协议,用于生成数字货币。这种数字货币必须具有与纸币相同的属性,即:
a. 只有银行能够铸造货币单位
b. 买卖双方的交易没有可追踪性
c. 银行公开一个单向函数f(•)和一个RSA公钥(n, e)。相应的私钥d保密。
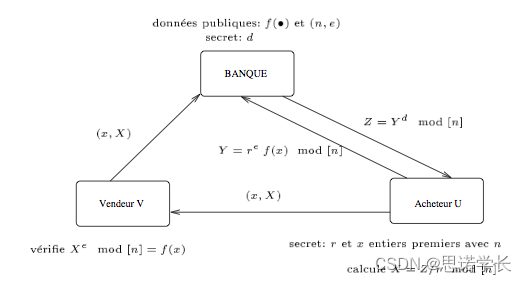
d. 购买者使用银行的服务来产生一个货币单位(x, X),卖家验证货币单位的有效性,即确保购买者确实使用了银行的服务来产生这个单位。方法如图所示。
6.1.1 问题13.1
6.1.1.1 问题
交易的匿名性是如何保证的?
6.1.1.2 问题解答
银行公开一个单向函数 f(•) 和一个 RSA 公钥 (n, e) [n, RSA模数;e, RSA 加密指数]。她保密 RSA 解密指数 d。该协议的连续步骤如下:
a. 购买者生成整数 r 和 x 并保密。他使用银行的公开值计算并将 Y 传送给银行。
b. 银行用其私钥 d 计算 并将 Z 传给购买者。银行从购买者账户上减去一个单位。
c. 购买者然后计算 X = Z/r mod [n]。这对 (x, X) 作为货币单位传给卖家。
d. 卖家确保它是一个有效的货币单位,即购买者确实使用了银行的服务来产生这对 (x, X)。为此,他验证 f(x) = X^e mod [n],否则他将拒绝这对 (x, X)。
e. 卖家将这对 (x, X) 提交给银行,银行在卖家账户上增加一个单位。
我们注意到在第 2 步中,数量 Y 等于。
然后在第 3 步中,购买者计算 Z/r mod [n],因此等于。
值得注意的是,购买者小心选择 r 与 n 互质,因此 r 在模 n 下是可逆的。
6.1.3 问题13.2
6.1.3.1 问题
什么保证了只有银行才能制造货币?
6.1.3.2 问题解答
购买者已经使用了银行的服务来计算数量。我们确信他确实与银行打交道,因为只有银行才能够铸造形式为
的数量,因为 d 是秘密的,并且 f(•) 是单向函数。事实上,如果一个冒名顶替者试图产生一对 (x, X) 使得
。冒名顶替者可能会随机选择一个 X 并使用公开值 (e, N) 来计算 X^e mod [n],但他则无法找到相对应的 x,因为 f(•) 是单向的。相反地,冒名顶替者可能会随机选择一个 x 并使用公开的函数 f(•) 来计算 f(x),但由于 d 是秘密的,冒名顶替者将无法计算
。
6.2 问题14 ;图的3-着色问题
6.2.1 问题背景
6.2.1.1 3-着色问题
给定一个有k个顶点的图G,图中有若干边,每条边连接图中的两个顶点。从一个顶点可以引出任意数量的边。
如果可以为图G的每个顶点指派三种颜色之一(例如,黄色、红色和蓝色),使得G中没有任何一条边的两个端点着相同的颜色,则称图G是3-可着色的。
3-着色问题是一个NP完全问题:如果G是一个任意的图,找到G的一个3-着色方案(如果它确实存在的话)是一个非常困难的问题。
6.2.1.2 零知识证明协议的三个原则
我们提出使用这个问题来构建一个零知识证明协议。回顾一下零知识证明协议的三个原则:
任何被授权的人总是能成功地认证自己,
未被授权的人最终总会暴露自己,
观察被授权的人进行认证的间谍不会学到任何能够用来认证自己的信息。
6.2.1.3 零知识证明协议在本问题的应用
在这个练习中,我们将考虑四个人物:证明者(Prouveur),验证者(Vérifieur),欺骗者(Tricheur)和间谍(Espion)。
证明者首先生成一个3-可着色的图:例如,他随机为k个顶点中的每一个分配一种颜色。然后,他随机生成顶点对(s1, s2),如果s1和s2没有被着上相同的颜色,则将s1和s2通过一条边连接。
他继续这个过程,直到例如所有他最初生成的顶点至少与其他两个顶点连接,并且图是连通的(总是存在从任意两个顶点s1到s2的路径)。按照这种方法构造的图是3-可着色的,并且他知道一种着色方案。
证明者公开他的图G,这样G就变成了公开信息,但他保留他的着色方案C作为秘密。
一个顶点s的颜色记为C(s),C(s)只能取三种可能的值:黄色,红色或蓝色。
此外,我们假设有一个众所周知的单向哈希函数h。
证明者想要向验证者证明自己的身份。协议的一轮进行如下:
1. 对于G中的每个顶点s,证明者随机抽取一个不同的随机数Rs(每轮和每个顶点的随机数都不同),并发送所有的哈希值h(s, C(s), Rs)给验证者。
2. 验证者随机选取G中由一条边相连的两个顶点s1和s2。
3. 证明者发送两个消息<s1, C(s1), Rs1>和<s2, C(s2), Rs2>给验证者。
4. 验证者计算这两个消息的哈希值,并核实这些值是否与证明者在第一步中给出的值相匹配。如果还满足C(s1) ≠ C(s2),则这一轮顺利完成。
使用这样的协议,显然证明者总是能成功地认证自己,因为他知道函数C。
6.2.2 问题14.1
6.2.2.1 问题
随机数Rs的作用是什么?如果从协议中系统地去除这些随机数会发生什么?如果对所有的顶点s使用同一个随机数R会怎样?
6.2.2.2 问题解答
随机数Rs的作用是确保每次证明过程中对于每个顶点发送的哈希值是独一无二的
随机数Rs的作用是为了掩盖颜色C(s)。如果没有随机数Rs,那么冒名顶替者可以计算3个可能的哈希值h(s, C),其中C=红色、黄色或蓝色,并通过将这三个哈希值与证明者宣布的h(s, C(s))进行比较来找到C(s)的值。
此外,如果对所有顶点s使用同一个随机数R,那么从证明者宣布了某个顶点s1的(s1, C(s1), R)起,冒名顶替者可以通过将h(s, C(s), R)与h(s, C, R)进行比较并测试C的3个可能值(红色、黄色、蓝色)来找出所有顶点的颜色。
6.2.2.3 问题的详细解答
确保哈希值的唯一性:随机数确保每次证明过程中,即使是相同的顶点和颜色组合,也会生成不同的哈希值。这样,每一轮的验证都是独一无二的,提高了协议的安全性。
掩盖颜色信息:通过将颜色信息与随机数一起哈希,随机数帮助隐藏真实的颜色值。如果没有随机数,攻击者或冒名顶替者可以通过计算和比较哈希值来揭露颜色信息。
防止颜色信息泄露:如果对所有顶点使用相同的随机数,那么一旦攻击者知道了一个顶点的颜色,就可以更容易地猜测或计算出其他顶点的颜色。这是因为相同的随机数
没有为每个顶点提供独立的 掩码 ,使得哈希值之间的比较可能揭示出颜色信息。
具体来说,如果对所有顶点使用相同的随机数
,冒名顶替者可以通过以下步骤来破解颜色:
证明者公布了某个顶点 的
。
冒名顶替者对于每个其他顶点,可以计算
对于每种颜色
(红色、黄色、蓝色)的值。
通过比较这些计算出的哈希值与证明者提供的哈希值,冒名顶替者可以推断出每个顶点的颜色。
这样,使用相同的随机数降低了协议的安全性,因为它使得攻击者通过比较和分析哈希值来推断颜色变得更加容易。因此,在设计零知识证明协议时,为每个顶点使用不同的随机数
是非常重要的,以确保每次验证的独立性和增强整个协议的安全性。
6.2.3 问题14.2
6.2.3.1 问题
我们现在来关注作弊者的情况。他不知道证明者的秘密(即G的3-着色方案),但仍然会尝试冒充证明者。因此,他获取了证明者的公开图G,并尝试按照3-着色规则对其进行着色。由于他不知道图是如何构造的,而且问题是NP完全的,他失败了。我们假设他能部分正确地对G进行着色。在他无法无冲突地着色的G的部分,作弊者犯了错误(即,边的两端颜色相同)。为了简化,我们认为他在着色时只犯了一个错误。他的着色因此是不完美的,在下文中我们记作C0。
作弊者决定采取以下态度。他在协议的第一步向验证者发送他的着色C0的哈希值。如果验证者询问他正确着色的一条边(s1,s2),他发送消息<s1, C0(s1), Rs1>和<s2, C0(s2), Rs2>。
如果验证者询问他未能正确着色的边,他会发送例如<s1, 黄色, Rs1>和<s2, 红色, Rs2>的消息,只要两种颜色不同即可。作弊者能以这种方式欺骗验证者吗?
6.2.2.2 问题解答
作弊者不能以这种方式混淆验证者,因为在第一步中,他已经对<s1, C0(s1), Rs1>进行了"承诺",通过传输量h(s1, C(s1), Rs1)给验证者(对于顶点s2也是同样的情况)。这意味着如果验证者随机选取的边恰好是作弊者无法正确着色的边,作弊者在第三步中发送的颜色信息将与他最初"承诺"的信息不符,验证者通过哈希值就能发现作弊者的不一致性,从而揭露作弊者的欺诈行为。
6.2.4 问题14.3
6.2.4.1 问题
如果哈希函数h构造不当,特别是容易发生碰撞,比如对于任意的顶点s和颜色c以及任何数r,都能相对容易地找到另一种颜色c0和一个随机数r0,使得h(s, c, r) = h(s, c0, r0)。在这种情况下,证明作弊者即使不知道图G的3-着色方案,也总能成功地认证自己。
6.2.4.2 问题解答
如果哈希函数h容易发生碰撞,那么当作弊者在某个他未能正确着色的顶点s上受到质询时,他可以对随机数Rs进行 撒谎 。他可以修改随机数Rs1和Rs2的值以保持与第一步中宣布的值的一致性,同时宣称颜色C(s1) = C(s2)。
6.2.5 问题14.4
6.2.5.1 问题
我们假设h是一个安全的哈希函数。设n是图G中边的数量。作弊者在一轮中成功认证的概率是多少?证明如果n很大,作弊者在n轮中成功认证的概率接近1/e。
6.2.5.2 问题解答
我们假设在n条边中只有一条边着色错误。如果每一轮提出的问题彼此独立,那么在一轮中被抓到的概率是1/n,而在n轮中不被抓到的概率是:。
如果n足够大,我们可以使用以下近似:
如果我们执行k轮协议,那么不被抓到的概率是(1 - 1/n)^k,当k趋向于无穷时,这个概率趋向于0。
6.2.5.3 数学公式
首先,是在一轮中没有被抓到的概率。为了估算这个表达式,我们取对数:
根据对数的幂规则,可以把指数拿出来:
当很大时,
就很小,我们可以使用泰勒级数的第一项来近似
,即:
因此,当时:
所以,可以写作:
那么大约是:
最后,是数学常数
(约等于 2.71828)的倒数,大约等于 0.367879441...,这意味着作弊者在一轮中成功认证自己的概率大约是
。
当n足够大时,通过重复这个过程n轮,我们可以得到作弊者在所有n轮中都成功认证自己的概率,使用同样的逼近方法,得到的结果接近于。这种情况下,如果n轮都是独立的,作弊者在所有轮中都不被发现的概率随n增大而减少,最终趋向于
。
6.2.6 问题14.5
6.2.6.1 问题
因此,我们可以看到,通过增加轮数,作弊者最终总会暴露自己。现在,我们将关注间谍的情况:他观察了证明者的所有认证过程,希望从中获取足够的信息来冒充证明者。如果使用前述协议,展示间谍最终能完全发现证明者的着色方案。
6.2.6.2 问题解答
在每一轮中,证明者会透露两个顶点的颜色。逐渐地,间谍学会了图的着色方案。
6.2.7 问题14.6
6.2.7.1 问题
通过这种修改,证明者在每一轮的第一步开始前,随机改变其着色约定:他会随机交换初始着色方案中三种颜色的名称。在协议的第三步中,证明者才明确透露关于他着色方案的信息。有了这种修改,间谍能从消息中推断出什么信息?
6.2.7.2 问题解答
随着证明者在每一轮中随机改变颜色名称的约定,间谍从任何特定轮次获取的信息将无法直接用于识别证明者的确切颜色方案。
换句话说,即使间谍知道某两个顶点在特定轮次中不共享相同的颜色,由于颜色名称的随机置换,间谍无法确定这些颜色在证明者原始着色方案中的确切身份。因此,这种修改极大地减少了间谍能够从每轮交流中收集到的有效信息量,实际上使他无法从观察到的颜色分配中学到任何有关证明者原始着色方案的具体信息。
6.2.7.3 关于间谍的解释
这段文字描述了一个零知识证明过程中对于防止作弊者和间谍获取有效信息的策略。在原始的协议中,通过多轮验证,作弊者尝试冒充合法证明者的行为最终会被揭露。对于间谍,他通过观察证明者的所有认证过程,希望能够获取足够的信息来模仿证明者。在没有修改前的协议下,间谍通过每一轮中证明者透露的两个顶点的颜色信息,逐步学习到整个图的着色方案。
为了阻止间谍学习到有用的信息,协议被修改为在每一轮开始之前,证明者会随机改变颜色的标记(即颜色的命名或指派)。这意味着,即便间谍在某一轮中得知了两个顶点的颜色不同,由于颜色标记在每轮都会随机变化,间谍无法确定这些颜色在证明者的原始着色方案中对应哪些具体颜色。因此,这种协议的修改大大降低了间谍通过观察获取有用信息的能力,使其不能通过观察得到的颜色分配信息来准确了解证明者的原始着色方案。
简而言之,这种协议的修改有效地保护了证明过程的安全性,防止了间谍和作弊者通过分析验证过程中的信息来破解或模仿合法证明者的身份。
6.2.8 问题14.7
6.2.8.1 问题
与像Fiat-Shamir这样的协议相比,这个协议的主要缺点是什么?
6.2.8.2 问题解答
密钥的大小。
这个问题涉及到零知识证明协议的一个重要方面:效率和实用性。
在零知识证明中,密钥的大小 通常指的是进行证明所需的数据量大小。一个零知识证明协议的效率,部分地由生成和验证证明所需的数据量来衡量。如果一个协议需要传输大量的数据才能完成身份验证,那么它可能在实际应用中效率低下,特别是在带宽有限或计算资源受限的环境下。
Fiat-Shamir协议是一种非交互式零知识证明协议,通过将交互式的步骤转化为非交互式的,使用哈希函数来代替验证者的随机挑战。这种转换减少了通信的需求,使得证明过程更加高效,尤其是在需要远程验证的场景中。
相比之下,上文讨论的协议,每一轮都需要证明者和验证者之间的交互,并且证明者需要为图的每个顶点生成和发送额外的信息(如随机数和颜色的哈希值)。如果图很大,或者为了达到高安全性需要执行许多轮,那么所需传输的数据量也相应增加。此外,证明者还需要在每轮开始前随机改变颜色约定,这增加了协议的复杂性。
因此,与Fiat-Shamir协议相比,这个协议的主要缺点是可能需要更大的密钥(或证明数据)大小,从而影响了它的通信效率和实用性。
6.3 问题15:背包问题
6.3.1 问题背景
给定正整数a1, a2, ..., ak。设M是一个整数,且M < Σ from i=1 to k of ai。我们想要解决方程M = Σ from i=1 to k of ei * ai,其中ei ∈ {0, 1}。这个问题称为背包问题,其在一般情况下是一个NP完全问题。
6.3.2 问题15.1
6.3.2.1 问题
假设对所有的i ≥ 2,都有ai > Σ from k=1 to i-1 of ak。这时我们称之为超递增背包。展示此时的问题很容易解决。
6.3.2.2 问题解答
假设背包是超递增的,即ai > Σ from j=1 to i-1 of aj。在这种情况下,我们考虑最大的物品,如果它能放进背包,我们就放进去;换句话说,如果ak ≤ M,则ek = 1。实际上,我们知道所有其他物品的累积体积不足以填满背包;事实上,Σ from j=1 to k-1 of aj < ak ≤ M,因此即使我们将所有的ek设置为1对于所有k < j,也无法达到M。然后,我们用容量为M - ek * ak的背包和物品a1, a2, ..., ak-1重复同样的推理,这同样是一个超递增背包。每次我们都取剩余物品中最大的;如果它能放进背包,我们就放进去,否则我们就排除它,继续下一个。
6.3.3 问题15.2
6.3.3.1 问题
设a1, a2, ..., ak是一个超递增背包。
设N > Σ from i=1 to k of ai,且N与所有的ai(i=1到k)互质。
设A是与N互质的一个整数。
我们定义。
设C = Σ from i=1 to k of ei * bi,其中ei ∈ {0, 1}。
证明如果我们知道A和ai,那么可以根据C找出ei的值。
6.3.3.2 问题解答
N是一个素数,且对于所有形式为M = Σ from i=1 to k of ei * ai(其中ei ∈ {0, 1})的整数M,都有N > M。
A与N互质,因此在模N下可逆。
我们有C = Σ from i to k of ,其中bi = ai * A mod [N],并且a1, a2, ..., ak是一个超递增背包。
如果我们知道A、N和bi(或等价地知道ai),我们可以计算:
= Σ from i=1 to k of ei * ai
这样我们就面临一个有超递增背包的背包问题。因此,我们可以很容易地找到ei的值。
简单来说,如果我们有超递增背包的参数和某些特定操作(如乘以A和取模N)所生成的结果C,通过使用A的逆元在模N下对C进行操作,我们可以将问题转化回原始的超递增背包问题,从而较容易地解决它,即找出构成C的原始系数ei。这个过程的关键在于A的逆元能够"解密"出通过加权和构成的C,从而揭示出加权系数ei,这对于解决背包问题非常关键。
6.3.3.3 问题详细解答
要理解这一点,首先需要知道模运算中的逆元概念以及它如何工作。在模N运算中,如果有两个数A和B,使得(A * B) mod N = 1,则称B是A在模N下的逆元,记作A^(-1)。这意味着A与其逆元B相乘后,模N的结果是1。
现在,考虑到我们有C = Σ(ei * bi) mod N,其中bi = (ai * A) mod N。我们想要从C中“恢复”出原始的ai值,或者更准确地说,我们想要通过C来推断出ei值,因为每个ai是已知的,并且我们假设ai构成一个超递增序列。
如果我们对C乘以A的逆元(A^(-1)),并取模N,我们得到的是:
(A^(-1) * C) mod N = (A^(-1) * Σ(ei * bi)) mod N
将bi的定义(ai * A mod N)代入上式,我们有:
= (A^(-1) * Σ(ei * (ai * A mod N))) mod N
因为模N运算的一个性质是(ab mod N) * c = ac * b mod N,我们可以将A^(-1)分配到求和符号内部的每一项,并利用A * A^(-1) = 1的事实:
= Σ(ei * (ai * (A * A^(-1)) mod N)) mod N
= Σ(ei * ai) mod N
这里我们使用了A与其逆元相乘等于1的性质,而这个乘积对模N来说是等价的,这意味着在模N下,A和A^(-1)的乘积消除了A的影响,使我们能够直接得到Σ(ei * ai) mod N,即没有“变形”的原始求和表达式。
这正是我们所需要的,因为如果ai构成一个超递增序列,那么就可以容易地通过这个求和表达式来确定哪些ei是1(即哪些ai被选中了)。因此,利用A的逆元确实可以让我们通过C来“逆向操作”找回ei的值。
6.3.4 问题15.3
6.3.4.1 问题
由此推导出一个使用公钥的协议,以编码一个k位的消息。
6.3.4.2 问题解答
公钥是背包 b1, b2, ..., bk。私钥是整数 A。整数 a1, a2, ..., ak 也保持秘密。明文消息是二进制序列 e1e2 ... ek,加密消息是整数 C = Σ from i=1 to k of ei * bi。
6.3.4.3 详细解答
在这个公钥加密系统中,解码之所以可行,是因为私钥持有者拥有一些额外的信息(即私钥A及超递增序列a1, a2, ..., ak),这些信息使得他们能够逆转加密过程。
公钥(b1, b2, ..., bk)是通过将私钥A和超递增序列中的每个元素相乘并取模N得到的。由于A是与N互质的,因此A在模N下有逆元A^(-1)。
这意味着使用私钥A,我们可以从加密的消息C中恢复出原始的二进制序列e1e2 ... ek。
6.3.4.4 如何解码
使用私钥A的逆元:首先,解码者(私钥持有者)需要计算A的逆元A^(-1)。这可以通过扩展欧几里得算法实现。
逆转加密过程:然后,解码者用乘以加密消息C,并对结果取模N,即计算(A^(-1) * C) mod N。这个操作实际上是在逆转公钥加密的过程。
利用超递增序列解背包问题:结果是加权超递增序列的和的模N。因为a1, a2, ..., ak形成一个超递增序列,解码者可以通过贪心算法从最大的ai开始,逐个检查每个ai是否能够被包含在和中(即检查去除ai后是否能够得到剩余的和)。这样,解码者可以确定每个ei是0还是1。
总的来说,解码过程利用了私钥A的逆元来逆转加密过程,并依赖于超递增序列的性质来恢复出原始的二进制序列e1e2 ... ek。这个过程是高效的,因为超递增序列的性质使得解背包问题变得简单。
6.3.5 问题15.4
6.3.5.1 问题
为一个能编码1字节的协议计算密钥。公钥和消息的大小是多少?与能编码一个字节的RSA进行比较。结论是什么?
备注:这个加密算法是第一个被发明的公钥加密算法(早于RSA一年)。它之所以被放弃,是因为即使不知道A,使用适当的数学工具也能解码。
6.3.5.2 问题解答
为了加密一个k位的消息,我们需要使用一个由k个整数组成的密钥。因此,密钥比消息要长得多。这是这个协议被放弃的原因之一。
在这个加密协议中,每个比特(bit)的加密都需要一个对应的整数。这意味着,如果我们想要加密一个k位的消息,我们需要一个包含k个整数的密钥。比如,如果消息是一个8位的字节(byte),那么加密这个字节就需要8个整数。每个整数都可能是一个大数,尤其是当涉及到公钥加密和模运算时,这些数通常需要非常大以确保安全性。
由于每个比特都对应一个整数,所以密钥的长度(以位为单位)远远超过了消息本身的长度。这导致了几个问题:
1. 效率低下:加密和解密过程需要处理大量的数据,这可能会导致性能问题,尤其是在处理能力有限的设备上。
2. 存储和传输问题:由于密钥非常长,它们的存储和传输都可能成为问题。在需要频繁交换密钥的场景中,这种问题尤为明显。
3. 与其他加密协议相比的劣势:例如,RSA加密协议允许使用相对较短的密钥来加密较长的消息。与之相比,需要为每个比特准备一个整数的加密方法在实际应用中显得不够实用。
正因为以上原因,尽管这个基于背包问题的加密协议在理论上是可行的,但在实际应用中,它的这些限制导致了它最终被其他更高效、更实用的加密协议所取代。
6.4 问题16:Fiat-Shamir协议
6.4.1 问题背景
在接下来的讨论中,我们接受以下结果:设p和q是两个素数,且N = p * q,那么根据,无法猜测X的值。
这个关于二次剩余的问题是一种无需知识转移的身份验证协议——Fiat-Shamir协议的基础。
Alice想要向Bob证明她的身份。她选择N = p * q,p和q是两个素数,她选择了一个数X(0 < X < N)。她计算Y = X^2 mod [N]。她公布了(Y, N)这对数字,Bob将其保存,而她保密X,并销毁了p和q。
每当她想要向Bob证明自己的身份时,她就需要证明她持有X,但同时又不透露X的实际值。
6.4.2 问题16.1
6.4.2.1 问题
考虑以下协议:Alice生成一个随机数a(0 < a < N)。她计算,然后将y发送给Bob。
Bob确认收到y后,Alice随即发送x = a * X给Bob。Bob接着验证y = x^2 mod [N]。
我们来证明Eve(一个未被授权的第三方)如何在不知道秘密X的情况下,如何冒充Alice通过认证。
6.4.2.2 问题解答
Eve不知道X,她应该如何操作呢?Eve随机选择一个x,并向Bob发送y = x^2 mod [N]。然后,她再向Bob发送x,Bob验证后发现y确实等于x^2 mod [N],从而认为验证通过。这证明了在协议中需要添加一个“承诺”步骤(关于a的值),以限制Eve必须以x = aX mod [N]的形式正确构造她的x。
6.4.3 问题16.2
6.4.3.1 问题
Alice生成一个随机数a(0 < a < N)并向Bob发送量t = a^2 mod [N]。
Bob随机抽取一个变量ε,该变量等概率地取0或1,并将ε通知给Alice。
如果ε=0,Alice将a发送给Bob,Bob验证t = a^2 mod [N]。
如果ε=1,则Alice发送aX mod [N]给Bob,Bob验证(aX)^2 mod [N] = tY mod [N]。
数字a的作用是什么?变量ε的作用是什么?
6.4.3.2 问题解答
数字a是一个随机掩码,用于不直接传输秘密X。
变量ε对应于一个“挑战”,即Bob向Alice提出的问题。我们可以考虑如果从协议中去掉这个随机的ε会发生什么。
6.4.4 问题16.3
6.4.4.1 问题
假设Eve想要冒充Alice进行身份验证。她事先监视了Alice的身份验证过程。
我们进一步假设Bob使用的随机生成器ε对Eve是已知的。那么展示Eve如何始终能够代替Alice进行身份验证。
6.4.4.2 问题解答
如果系统地让ε=0,那么任何人(Eve)都能认证成功,因为Alice的回答中不涉及秘密X。
如果系统地让ε=1,那么Eve可以按照以下方式操作。
她知道Bob的问题将是ε=1,即“给我一个x₀(假设等于aX mod [N])使得x₀² = tY mod [N],其中t是你在第一步传给我的值。”
Eve接着这样操作:她随机计算一个x₀,并设置t = x₀²Y⁻¹ mod [N];这个t的值在第一步传给Bob。
备注:Y在模N下是可逆的,因为如果不是,那就意味着Y与N不互质,即Y等于p或q,但Y是模N的一个平方,而p和q是质数。
6.4.5 问题16.4
6.4.5.1 问题
Eve并不完全知道Bob使用的随机生成器,但她尝试提前预测Bob将会提出的值。她能够以概率p确定ε的值。Eve在一个回合中正确认证的概率是多少?在k个回合中呢?
6.4.5.2 问题解答
k元组(ε1, ε2, ..., εk)的状态空间的基数是2^k,用作随机掩码。
当我们看到相同的k元组重现的平均时间比只有一个ε在{0, 1}中取值的情况要长得多。例如,如果生成器是无偏的,那么周期是N^k而不是N。
这个解答说明了在多轮验证过程中,Eve预测Bob随机挑选的ε值(挑战)的可能性。在单轮中,ε的可能值有两个(0和1),所以Eve正确预测的概率是p。在k轮验证过程中,整体的状态空间(即所有可能的ε值组合)的大小为2^k,这表示有2^k种不同的挑战序列可能出现。
如果Eve能够在每一轮中以概率p猜对Bob的挑战(ε值),那么Eve在k轮验证中全部猜对的概率是p^k。这是因为Eve需要在每一轮中都正确猜测,而各轮是独立的,所以概率相乘。
如果Bob使用的随机数生成器在每次生成ε时都完全随机(即生成0和1的机会相同,没有偏差),那么在进行多轮验证时,整个验证过程中出现相同的ε值序列(比如连续几轮都是0或1的特定组合)的周期会随着验证轮数的增加而显著增长。
具体来说,如果只有一轮验证(k=1),那么出现0或1的周期是N(这里的N可以理解为产生重复模式前的尝试次数)。但如果有k轮验证,那么出现特定的ε值序列(比如001, 010等)的周期将是N的k次方(N^k)。这是因为随着验证轮数增加,可能的ε值序列组合数量以指数形式增加。
这意味着,随着验证轮数的增加,Eve(或任何攻击者)想要预测出整个序列变得越来越困难,因为可能的序列组合越来越多,重复特定序列的平均时间也就越长。因此,在多轮验证中使用随机挑战可以显著增加系统的安全性,使得未授权者成功冒充的概率大大降低。简单地说,这就是为什么在安全协议中通过增加验证轮数来提高安全性的原因。
6.4.6 问题16.5
6.4.6.1 问题
现在假设Bob的生成器是均匀分布的且保密的。相反,Alice的生成器设计不当,导致a的一个值以远高于1/(N − 1)的概率出现。Eve监视了所有的认证过程。她平均需要监视多少次认证才能够代替Alice进行认证?
6.4.6.2 问题解答
ε是真正随机且等概率的。相反,a的分布并不是完全均匀的,其中一个值以概率p出现,这个概率大于其他值。
这个问题暗示了经过一段时间,我们会看到a的相同值重现,而Eve将有机会观察到两轮使用了相同a值的情况。
Eve因为在协议的第一步看到相同的t值而意识到这一点。如果Eve更加幸运,这两轮的ε值将会不同,即一次ε=0,一次ε=1。那么Eve最终会看到a的相同值出现两次,以及aX mod [N]的值,只要a在模N下是可逆的(这是非常非常可能的),Eve就能找到X的值。这平均发生在迭代次数达到2/p时。
6.4.7 问题16.6
6.4.7.1 问题
协议以如下方式修改:Alice秘密地知道一组数字X1, X2, ..., Xk,并公布相对应的数字Y1, Y2, ..., Yk。
Bob不再发送一个单一的比特ε,而是发送K个比特ε1, ε2, ..., εk。然后Alice必须提供a乘以所有εi=1时的Xi的乘积。这种修改的好处是什么?
6.4.7.2 问题解答
k元组(ε1, ε2, ..., εk)的状态空间的基数是2^k,它作为随机掩码。在出现相同的k元组之前的平均时间,远远长于只有一个ε在{0, 1}中取值的情况。例如,如果生成器是无偏的,那么周期是N^k而不是N。
6.5 问题17:对El Gamal签名方案的存在性伪造攻击
6.5.1 问题背景
6.5.1.1 存在性伪造攻击
存在性伪造攻击是针对签名方案的一种攻击机制,通过该机制,攻击者能够展示一个有效的消息/签名对。
在这种类型的攻击中,消息不是随意的,而是由攻击者构造的,以便他能够产生相应的签名。与之相对的,在一种通用伪造攻击中,攻击者能够对所有消息进行签名。
6.5.1.2 El Gamal签名
我们将展示El Gamal签名方案对存在性伪造攻击是敏感的。首先回顾一下El Gamal签名方案。
El Gamal签名方案是一种基于离散对数问题的公钥签名算法。这里简单解释一下其工作原理和存在性伪造攻击的概念:
密钥生成:签名者选择一个素数p和Zp*的一个生成元g。他均匀随机地选择x ∈ Zp-1,并计算。公钥是(p, g, y),私钥是x。
签名:为了签名一个消息m ∈ Zp-1,签名者均匀随机地选择k ∈ Zp*-1,并计算。然后计算
,签名是对(r, s)。
验证:一个对(r, s)是m ∈ Zp-1的有效签名当且仅当(r, s) ∈ Zp × Zp-1且
6.5.1.3 El Gamal签名方案的基本步骤
6.5.1.3.1 密钥生成
选择一个大素数p和一个原根g,其中g是的生成元。
随机选择一个私钥x,x是一个小于p的正整数。
计算公钥。
公钥为,私钥为x。
6.5.1.3.2 签名过程
对于一个给定的消息m,签名者选择一个随机数k,k与互素。
计算。
计算。
签名为一对。
6.5.1.3.3 验证过程
验证者接收到,检查
是否成立。如果等式成立,签名有效。
6.5.1.4 存在性伪造攻击
存在性伪造攻击是指攻击者能够构造出一对有效的消息/签名,而不需要知道私钥
。这种攻击不需要攻击者选择特定的消息来签名;相反,攻击者构造出签名后,找到与之对应的消息。
在提出的攻击策略中,攻击者选择r和s,然后反向计算出一个,使得
符合El Gamal签名的验证等式。例如,攻击者可以设置
,然后选择一个s,最终计算出一个
,使得签名看上去是有效的。这种攻击展示了El Gamal签名在某些情况下可能面临的安全风险。
总的来说,存在性伪造攻击揭示了El Gamal签名方案在特定条件下可能被攻破的可能性,这强调了在实际应用中需要考虑更高安全性的签名方案或采用额外的安全措施。
6.5.2 问题
攻击策略:假设攻击者设定,然后计算
。那么对(r, s)是哪个消息的有效签名?
6.5.3 问题解答
攻击者以的形式伪造r,然后计算"签名"
。
在验证者那里,为了让签名被视为"有效",必须满足:
因此,如果,那么
就是m的有效签名。
7. 信息论的问题
7.1 问题18: Geffe生成器
7.1.1 信息论回顾
7.1.1.1 熵
衡量随机变量X的不确定性的量。如果X的可能值很多且每个值出现的概率都差不多,那么X的熵就很高,因为我们很难准确预测X会取哪个值。熵越高,X的不确定性越大。
设X是一个取离散值x的随机变量,其概率为p(x)。根据定义,X的香农熵(Shannon entropy)为:
如果对数的底数为2,则熵以比特(信息)为单位表示。熵是对X值不确定性的量化测量。等效地,它是观察到事件X=x平均提供的信息量。
7.1.1.2 条件熵
在已知随机变量Y的值的情况下,随机变量X的不确定性。条件熵给我们提供了当我们知道变量Y的信息后,X剩余不确定性的量化。如果Y给我们提供了关于X很多信息,那么H(X|Y)将会很小,因为知道Y后,X的不确定性减少了。
设X和Y是两个随机变量。如果我们以特定事件Y=y为条件,我们可以关注条件概率分布[X | Y=y](知道Y=y的条件下X的分布)的熵:
这里p(x | y)表示条件概率P(X=x | Y=y)。
如果我们考虑Y的所有可能值,并且以概率p(y)为权重,我们得到X知道Y的条件熵:
这是观察Y后对X剩余不确定性的平均测量。
7.1.1.3 互信息
衡量变量X和Y之间相互提供的信息量,即知道Y能减少关于X不确定性多少,反之亦然。互信息高意味着X和Y高度相关,一个变量的信息能显著减少对另一个变量不确定性的量。
X和Y之间的互信息是观察Y带来的关于X不确定性的减少;换句话说:
可以证明这个量是对称的:
也可以容易地表达为(X, Y)的联合概率分布以及X和Y的边缘概率分布的函数:
简单来说,熵是衡量随机变量不确定性的;条件熵是在知道另一随机变量的值后,原随机变量不确定性的量度;互信息是两个随机变量之间共享信息的量度,即一个变量减少另一个变量不确定性的能力。
7.1.2 问题18.1
7.1.2.1 问题
考虑3个并行耦合的伪随机序列(ak)k∈N, (bk)k∈N 和 (ck)k∈N,通过Geffe生成器组合:sk = akb̅k ⊕ bkck。
ak和sk之间的互信息是什么?
7.1.2.2 问题解答
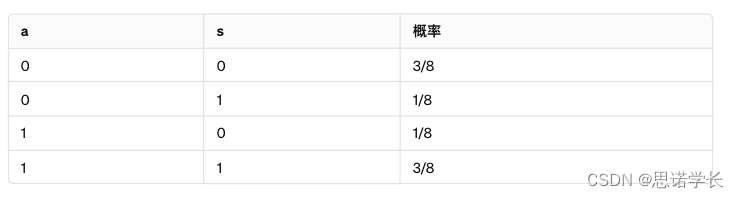
假设每个伪随机序列ak, bk和ck都是平衡的,即它们以等概率取值0或1。我们关注(ak, sk)对的分布。
在此之前,我们将考虑(a, b, c)的所有可能值(这些值是等概率的,为1/8),并找到对应的s值。
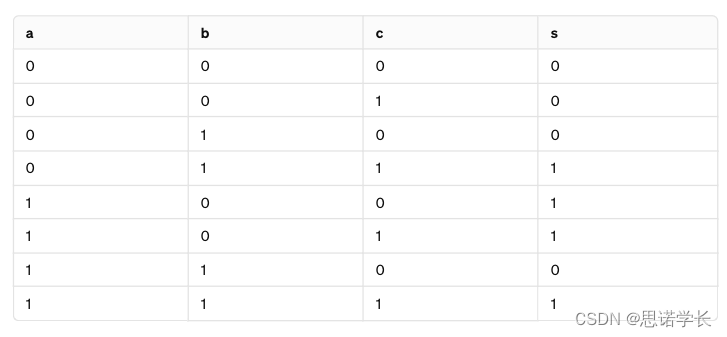
据此,我们推导出(a, s)对的概率。
互信息是指观察到s后对a不确定性的减少(反之亦然):
I(a, s) = H(a) − H(a|s) = H(s) − H(s|a)
例如,我们将使用公式H(a) − H(a|s)。因为a是一个等概率的二元变量,所以我们有H(a) = 1(信息位)。此外,我们计算了在s的一个特定值条件下a的熵:
如果s = 1,则a = 0的概率为1/4,a = 1的概率为3/4。
如果s = 0,则a = 1的概率为1/4,a = 0的概率为3/4。
因此,我们可以计算以下条件熵:
H(a | s = 1) = H(a | s = 0) = −(1/4) log(1/4) − (3/4) log(3/4) = (1/4) × 1.38 + (3/4) × 0.29 = 0.345 + 0.2175 = 0.56
从而,我们推导出a和s之间的互信息:
I(a, s) = 1 − 0.56 = 0.44比特
7.1.3 问题18.2
7.1.3.1 问题
假设序列ak是由一个已知结构的LFSR(线性反馈移位寄存器)产生的。秘密是LFSR的初始值(密钥)。提出针对Geffe生成器的可能攻击。
7.1.3.1 问题解答
我们将利用生成器的输入a和输出s之间不是相互独立的这一事实。对于产生序列a的LFSR的每个初始值,我们将计算序列a与观察到的输出s之间的相关性。如果这种相关性显著不为0,那么很有可能我们已经找到了密钥。如果LFSR的长度为L,那么需要测试的值的数量为2^L。
7.2 问题19: 完美保密
假设一个加密系统,其中M = {a, b, c},C = {1, 2, 3, 4},K = {k1, k2, k3},加密/解密操作由下表给出:
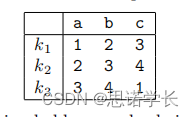
假设密钥是等概率的,密钥的选择与要加密的明文独立,并且明文的概率分布由PrM(a) = 1/2, PrM(b) = 1/3, PrM(c) = 1/6给出,计算H(M), H(C), H(K), H(K|C)和H(M|C)。这个加密系统是否具有完美保密性?
解决方案:
H(M) = −(Pr(M = a) log2(Pr(M = a)) + Pr(M = b) log2(Pr(M = b)) + Pr(M = c) log2(Pr(M = c))) ≈ 1.46
密钥等概率因此 H(K) = log2(密钥数) = log2(3) ≈ 1.58
对于每个密文j = 1, 2, 3, 4,我们有 Pr(C = j) = ∑从i=1到3 Pr(C = j|K = ki) · Pr(K = ki)。这给出数值


我们得出熵的值
- H(C) ≈ 1.95
- H(K|C) ≈ 1.09
- H(M, C) ≈ 3.04
- H(M|C) = H(M, C) - H(C) ≈ 1.09
这个加密系统不具备完美保密性。
在您提供的图表中,我们有两个条件概率分布表,分别是密钥K给定密文C的条件概率,以及明文M给定密文C的条件概率
。这些表格提供了在已知密文的情况下,密钥或明文取特定值的概率。
为了计算这些条件概率,我们首先需要理解加密过程和给定的概率分布。然后根据这些分布,我们可以使用总概率定理来计算密文概率,然后用这些概率来找到条件概率
和
。
根据您的图表:
1. 表格说明了,例如,当密文为1时,密钥
的概率是3/4,
是0,
是1/4。
2. 表格说明了,例如,当密文为1时,明文a和密文1的联合概率是1/6,b是0,c是1/18。
有了这些信息,我们就可以计算信息熵和
:
- 是给定密文时密钥的条件熵,可以通过计算每个
并将它们放入熵公式来得到。
- 是给定密文时明文的条件熵,也是通过计算每个
并使用熵公式来得到。
例如,对于密文1:
-可以通过
来计算。
- 可以通过
来计算。
注意:0应被视为0,因为在信息论中,我们通常定义
,因为这代表了“不可能事件不提供信息”。
然后对于所有密文值1, 2, 3, 和 4重复这个计算过程,并将它们按概率加权求和,得到整体的和
。
8. 其他问题
8.1 问题20:同态加密
8.1.1 问题
同态加密是一种加密方法,它与某种数学运算(例如加法或乘法)具有可交换特性。对加密数据进行该运算的结果,解密后与对未加密数据进行同样运算的结果相同。
这种特性允许将计算任务委托给外部代理,例如不受信任的云计算服务,而不会使数据或结果暴露给该代理。
1. 证明RSA是乘法同态的。
2. 证明El Gamal是乘法同态的。
3. 证明Pailler加密系统是加法同态的。
8.1.2 问题解答
下面简要描述了Pailler加密系统的关键生成过程:
选择两个大的质数p和q(保密)
(模数RSA,作为公钥)
(作为私钥)
加密过程:
选择一个随机数r,则加密的密文为:
其中是明文消息。
我们不详述解密过程,因为这不是这个练习的目的。只需要考虑两个加密消息和
。它们的乘积
对应于什么?我们能从Pailler加密系统的这个特性中得出什么结论?
8.1.3 问题解答
8.1.3.1 RSA加密
设m和为两个消息,c和
为相应的密文。记N为模数,e为加密指数。我们有:
和
的密文等于
。因此,产品的密文确实等于密文的产品,这意味着RSA是乘法同态的。我们可以注意到这也适用于除法:
的密文是
。
8.1.3.2 El Gamal加密
我们考虑一个素数p和g,g是的生成元。
Bob想要给Alice发送一个加密消息。设a是Alice的秘密值,是她的公开值。Bob选择一个随机的秘密值b,计算
。如果M明文消息,Bob计算
,并将对
发送给Alice。为了解密,Alice计算
并恢复 M。
现在假设Bob有两个明文消息M和要传送。
他会选择两个随机的秘密值b和,计算
和
,以及
和
。他将对
和
发送给Alice。
如果我们考虑和
的乘积,Alice在计算
时,会恢复
,即两个明文消息的乘积。
El Gamal加密系统是乘法同态的。
8.1.3.3 Pailler加密
我们有:
和
因此,乘积为:
这对应于在随机数
下的密文。Pailler加密系统是加法同态的。
8.2 问题2:希尔密码
在希尔密码中,字母表中的每个字母由0到25之间的整数表示(拉丁字母表转换为模26的整数集Z/26Z)。
这是一种对m个字母的块进行加密的方法,它将一个块(x1, x2, ..., xm)转换为一个块(y1, y2, ..., ym),通过以下代数关系定义:
其中A是一个m阶方阵,其系数在Z/26Z中,所有计算都是模26进行的。
例如,对于m=2和矩阵,消息(10, 21)被加密为
解密一个块是通过将加密块与A的逆矩阵相乘来完成的。
一个在Z/26Z中的系数的方阵是可逆的,当且仅当其行列式在模26下是可逆的。此外,当m=2时,逆由以下公式给出:
1. 验证上述示例中的矩阵是否可逆,并计算其逆。验证解密密文c=(16, 21)得到的明文是否确实为m=(10, 21)。
2. 描述如何对希尔密码进行已知明文攻击。
3. 在m=2的情况下,如果明文消息是法语等自然语言,描述如何对希尔密码进行单独的密文攻击。
8.2.1 解答
1. ,并且3在模26下是可逆的
,其逆为9。因此矩阵A是可逆的。
它的逆由下面给出:
另外,
2. 我们可以构建线性方程组,未知数是作为密钥的矩阵的项。有足够多的方程后,可以确定这些项。
3. 我们依赖于双字母组合的频率。如果希尔密码在ECB模式下使用,这些频率会在密文中被找到。









![[漏洞分析] CVE-2024-6387 OpenSSH核弹核的并不是很弹](https://img-blog.csdnimg.cn/direct/f12369be83cc4793a2750cf7590aa811.png#pic_center)
![[C++][设计模式][组合模式]详细讲解](https://img-blog.csdnimg.cn/img_convert/6aa6060f04a9181ac40cdfe4a9cd9860.png)